

ベーシック アドベントカレンダー 15日目です。
はじめまして!ゆいです。
現在、 マーケターのよりどころ「ferret」 はリニューアルを終え、速度改善に取り組んでいます。
速度改善と言えば、画像圧縮!画像の圧縮といえば、WebP ですね!
 WebP とは
WebP とは
WebPは、非可逆圧縮と可逆圧縮の両方に対応する画像形式であり、サイトのページ速度を最適化する手段の1つです。PNGやJPEGと比較してサイズが小さく、リッチで高品質の画像を提供しながら、画像の圧縮率を高め、画像の読み込みプロセスを高速化します。
WebP の存在を知ったところで、
 「画像データがどう保持されているのか知ってるといいかも。」
「画像データがどう保持されているのか知ってるといいかも。」

 (... 保持??知らない...)
(... 保持??知らない...)
という会話から、WebPの構造を追ってみることにしました!
「知らないこと」を知るとわくわくしますよね!!!
 構造
構造
WebP の構造はざっくりこんな感じです。
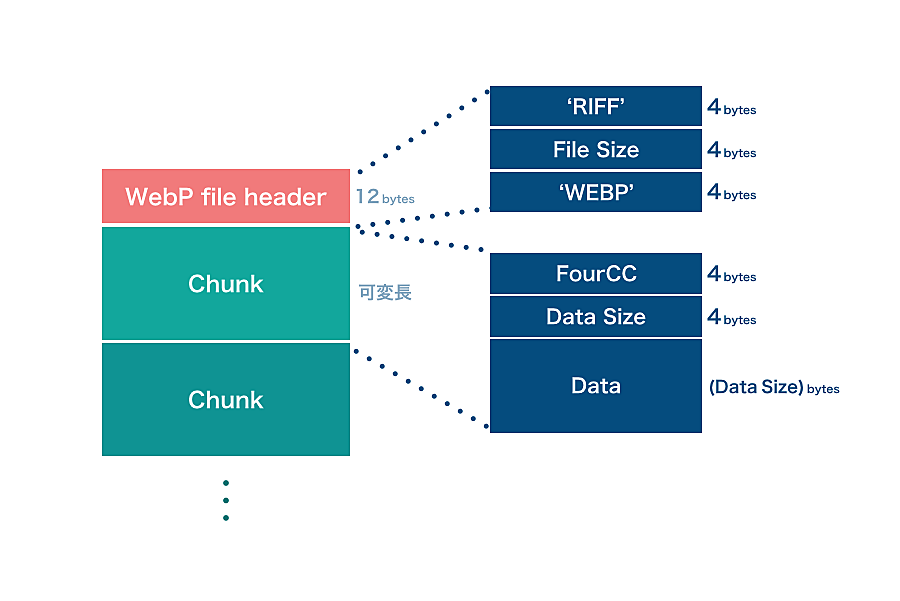
WebP Container Specification | Google Developers
 WebP ファイルのヘッダー
WebP ファイルのヘッダー
シグネチャです。
RIFF (Resource Interchange File Format)
WebP のファイル形式です。この形式をもとにデータが格納されています。
File Size ( 32ビット、リトルエンディアン )
画像ファイルの大きさです。
WEBP
WebP のデータであることを明示しています。
これらを踏まえて、ヘッダーの中身を読み込んでいきます。
今回使用する画像の情報
サイズが 20974 のwebp画像です。
20974 yui.webp
まずは、ヘッダーの情報から webpの画像であるかを確認します。
bin = File.binread('yui.webp')
riff = bin.slice!(0, 4)
file_size = bin.slice!(0, 4).unpack1('V')
four_cc = bin.slice!(0, 4)
puts "#{riff}, File Size: #{file_size}, FourCC: #{four_cc}"
出力
RIFF, File Size: 20966, FourCC: WEBP
Webp であることが確認できました。
ファイルサイズもだいたい一致していますね!
チャンクの読み込み
チャンクの構造をみていきます。
先頭の12bytes (header) は吹き飛ばし、中身を見てみます。
chunk_type = bin.slice!(0, 4)
chunk_data_size = bin.slice!(0, 4).unpack1('V')
chunk_data_size += 1 unless chunk_data_size.even?
chunk_data = bin.slice!(0, chunk_data_size)
puts "FourCC: #{chunk_type}, Chunk Data Size: #{chunk_data_size}, Chunk Data: <chunk_data>"
FourCC: ALPH, Chunk Data Size: 6608, Chunk Data: <chunk_data>
FourCC
チャンク内のデータが何かを表す識別子のようなものです。
初めの 4bytes は ALPH 。これは透過情報を表します。
実際に今回の画像は透過させているので、透過情報を含んだデータが取れてきてますね。
Chunk Data Size
チャンク内のデータサイズを教えてくれます。
次の 4bytes から、このチャンクのデータサイズが取れます。
Chunk Data
チャンク内のデータが格納されています。
チャンクサイズでわかったサイズ (6608) 分 slice するとこのチャンクのデータが取れます。
(データは、読んでいくことができませんでしたので省略 ♀️)
♀️)
この処理を繰り返すことで、WebP のデータが取れてきます。
チャンク の構造がわかってきたので、WebP ファイル全体の構造をみていきたいと思います。
def search_file(file)
bin = File.binread(file)
unless bin.slice(8, 4) == 'WEBP'
return puts 'Invalid file as webp'
end
# ヘッダー
riff = bin.slice!(0, 4)
file_size = bin.slice!(0, 4).unpack1('V')
four_cc = bin.slice!(0, 4)
puts "#{riff}"
puts "File Size: #{file_size}"
puts "FourCC: #{four_cc}"
# チャンク
until bin.empty? do
puts "*" * 30
chunk_type = bin.slice!(0, 4)
puts "FourCC: #{chunk_type}"
chunk_data_size = bin.slice!(0, 4).unpack1('V')
puts "Chunk Size: #{chunk_data_size}"
chunk_data_size += 1 unless chunk_data_size.even?
chunk_data = bin.slice!(0, chunk_data_size)
puts "Chunk Data: <chunk_data>"
end
end
結果!
[13] pry(main)> search_file('yui.webp')
RIFF
File Size: 20966
FourCC: WEBP
******************************
FourCC: VP8X
Chunk Size: 10
Chunk Data: <chunk_data>
******************************
FourCC: ALPH
Chunk Size: 6608
Chunk Data: <chunk_data>
******************************
FourCC: VP8
Chunk Size: 14320
Chunk Data: <chunk_data>
画像の情報は、チャンクごとに格納されていて、チャンクごとに取り出すことができました。
 妄想
妄想
ここからは疑問点の妄想です。
妄想なので、間違っていたら or 知っていたら、教えてください。
リトルエンディアン
RIFF の仕様から、数値はリトルエンディアンで格納されています。
リトルエンディアンは、データをメモリに格納する時に逆順でストアされます。
(店員から 1359円 を 「下の桁から 9531円 」ですと言われている感じですかね。)
リトルエンディアンだと何が嬉しいかを考えます。
- 最下位からからデータをストアしていくので、演算の際の効率が良いです。
(筆算で一の位から計算していくように。) - 可変に柔軟
仮に数値表現が2バイトから4バイトに変わったとしても、
一番下の桁が固定されているので後ろに2バイトの0をくっつけるだけで完結します。
unpack1('V')
ということで、
リトルエンディアンの unsigned long (32bit 符号なし整数) を解釈するような処理を書いています。
0でpadding
chunk_data_size += 1 unless chunk_data_size.even?
ここ処理は、次の一文によるものです。
The data payload. If Chunk Size is odd, a single padding byte -- that SHOULD be 0 -- is added.
データのサイズを見て、奇数の時は、データ部分が0でpadding される。
これも RIFF の仕様に沿った決まりのような気がします。
If the data is an odd length in size, an extra byte of NULL padding is added to the end of the data.
GFF Format Summary: Microsoft RIFF
なぜ偶数なのかは、答えが出ませんでした♀️
感想
はじめにバイナリコード見た時は吐きそうでした。
画像がどのようにデータを保持しているのかを、実際に取り出して確認するなんて、
できるとも思っていなかったので、感動しました。
多くの学びもあり楽しかったです!(エンディアンとか、チャンクの概念とか)
データの中身までは見れず... バイナリリーディングやっていきたいですね!
改めてコンピューターってすごいなあ…と身を以て感じました。