
こんにちは、PLG 事業部 開発部 部長の きのぴ です!
突然ですが障害対応って怖いですよね。でもプロダクト開発をしていれば、必ず直面するものだと思っています。この記事では、弊社で実際に障害対応の旗振り役になった場合、どんな動き方や心構えでいると良いかを書いてみたいと思い、ペンを走らせております✍
あくまでも弊社内でのルールに沿ったやり方ですので、参考例としてどうぞ!
まずは落ち着いて役割分担です
とにかく落ち着きましょう。焦っても障害は解決しません。
まず最初にやるべきことは役割分担です。
- カスタマーサポート(CS)さんに連絡する人
- 障害の事象を把握する人
- 原因を調査する人
- 対象ユーザーさんの連絡先(メールアドレスなど)をまとめる人
- 修正対応をする人やプルリクをデプロイする人
- 状況によっては変更差分をリバートする人
など、いろんな役割があります。
複数人で対応する場合、並列で処理ができるのでどんどん役割を割り振っていきましょう。
障害対応してくれる人を集める仕組みを作る
弊社では障害っぽいぞ?と思った時点で、遠慮なく /emergency_call という自作の Slack コマンドを叩いています。
このコマンドを使うと、開発やプロダクト、サポートチームのマネージャー以上のメンバーとインフラチームにグループメンションが飛びます。(大所帯)
そして障害対応専用のチャンネルに集まり対応を開始します。
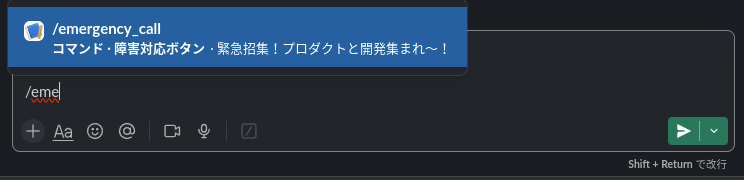
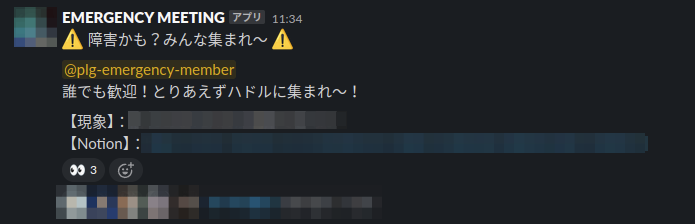
/emergency_call ◯◯ というように引数を渡すと【現象】の部分にメッセージが表示されます
Notion のタイトルにも採用されます、便利。
後述しますが、マニュアルと振り返りを Notion で管理しています。
想定以上に人が集まることがありますが、役割を割り振られていない人には解散してもらいましょう。
障害対応は即時対応が必要ですが、対応にかかるコストも非常に高いです。
手が空いてしまったら、それぞれのタスクに戻ってもらう方が効率的です。
障害の事象を把握する
兎にも角にも、まずユーザーさんへの影響を正確に把握しましょう。
- ページにアクセスできないのか
- 特定の機能が使えないのか
- いつから(いつまで)発生していたのか
- どのくらいのユーザーさんに発生しているのか
といったことを整理しておきます。
ユーザーさんへすぐに連絡する
弊社にはユーザーさんと直接やりとりするカスタマーサポート(CS)チームがあります。(いつもありがとうございます)
エンジニアが状況を把握できたら、すぐに CS チームに伝えてください。
ユーザーさんにすぐに連絡することで、不安をある程度和らげることができるのではないかと考えています。
CS チームはエンジニアが状況を把握している間に、あらかじめ用意されたテンプレートを元に案内文を作成してくれています。
- 発生日時
- 障害内容
- 影響範囲
などの情報を入れるだけで対応できるようになっています。
初期段階では対象のユーザーさんが特定できないことも多いので、その場合は SNS や、弊社では Headway などのプロダクト内通知で全体に先出しで告知します。
状況によっては全ユーザーさんにメールを送ることもあります。
原因の特定
なぜ障害が起きてしまったのか、原因を調査しましょう。
- 外部起因?
- 連携先で障害?
- インフラのパフォーマンス低下?
- さっきリリースした機能に不具合が?
- 実装漏れ?
- 要件漏れ?
- エラーログがないか?
- ローカル環境やテスト環境で再現するか?
- ...
事情によって原因を探る方法は異なるため、あらゆるアンテナを張っておく必要があります、大変ですよね😭
この内容だけで一本記事が書けそうなのでまたの機会に🙏
事象の把握と原因の特定は似ていますが別物だと考えています。事象の把握は各所への連絡や原因を正確に特定する準備のイメージです。
障害の解消対応
原因が特定できたら、次に障害を解消するための具体的な対応を決めます。
コードを修正するのか、リリースしたプルリクをリバートするのか、一時的にサーバーのスペックを上げるのかなど、原因に応じて適切に判断します。
障害の解消連絡
障害が解消したら、すぐにユーザーさんへ連絡します。
必要な情報をCSチームに伝えて、解消連絡をお願いしましょう。
障害を振り返る
障害は解消して終わりではありません。振り返りがとても重要です。今回の障害を再び発生させないようにしっかりと振り返ります。
- 原因は何だったのか
- どうすれば防げたか
- 障害に気づくまでの時間はどうだったか
- 気づくまでの時間を早めることはできたか
- 解消までの時間はどうだったか
- 解消までの時間を早めるには何ができるか
- 解消のために行った作業は一時的なものか、恒久的なものか
- 一時的なら、恒久的に解消するには何をいつまでにやるのか
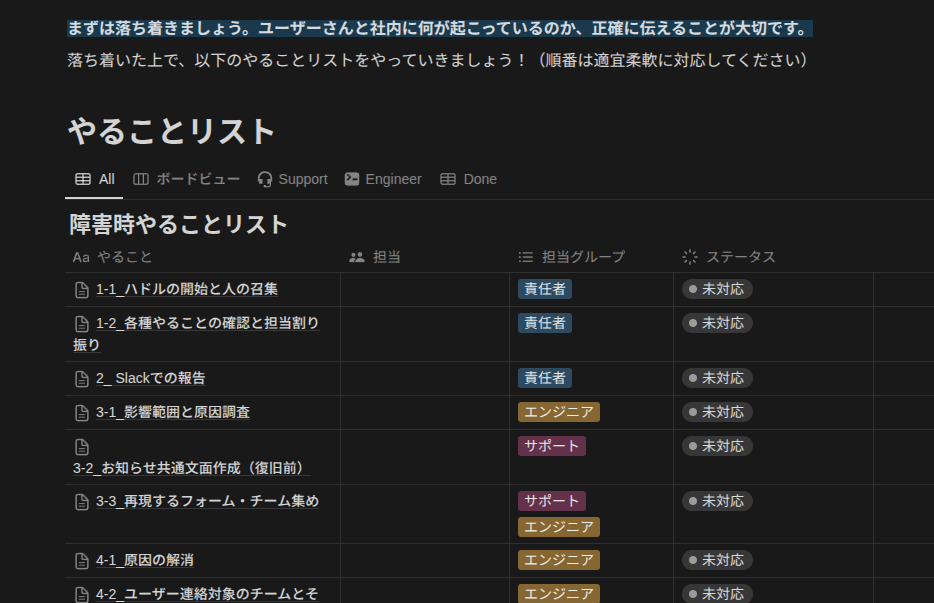
対応の流れをマニュアル化する
弊社には障害対応マニュアルがあり、自作の /emergency_call コマンドを使うと自動的に Notion にマニュアルが生成されます。
誰でも統一した対応ができるようにマニュアル化し、振り返りの内容(ポストモーテム的なやつ)もここで記録しています。
ハザードレベル表を作成する
障害はどれも緊急性が高いですが、さらにレベル分けすることで KPI 化したり、ステークホルダーへの連絡指標になります。
障害内容、影響範囲、影響時間、対象ユーザー数を掛け合わせてレベルを決定しています。

最後に
障害対応で一番大事にしたいのはユーザーファースト、顧客中心のマインドです。
ユーザーさんあってのプロダクトですので、まずはユーザーさんに情報を正確に素早く伝えて、少しでも不安を払拭していただくことが大事です。
「もしエンジニアのあなたが」と書きましたが、一番意識しておくと良いと思った部分は上記です。
エンジニア(主語がでかい、すみません、僕の知りうる範囲です)はまず原因から探ろうとしますが、それより前に何が起きているのかを把握して伝えることが大事だと考えています。
原因から探りたい気持ち、とてもわかります🥲
自分もそうです、だって自分が書いたコードが原因だったら嫌だもん。
けど起きたことは仕方ないんです、次に活かしましょう!
大事にしたいもう一つの観点として、誰も責めないことです。
障害は誰か一人のせいではなく、チーム全体の問題です。
起きたことは仕方ないんです、次に活かしましょう(2回目)
正直、障害を完全に防ぐのは不可能です、すみません、ごめんなさい。
ですが、発生を抑えたり、解消までのスピードを上げることはできます、やります!
障害対応は非常にコストがかかります。だからこそ、抑える、発生しても即解決する姿勢が重要です。
しっかりと振り返って、仕組みで改善していきます。
障害対応してくださっているみなさん、いつもありがとうございます🙇
障害に強いチームを作って、楽しくプロダクト開発をしていきましょう!