
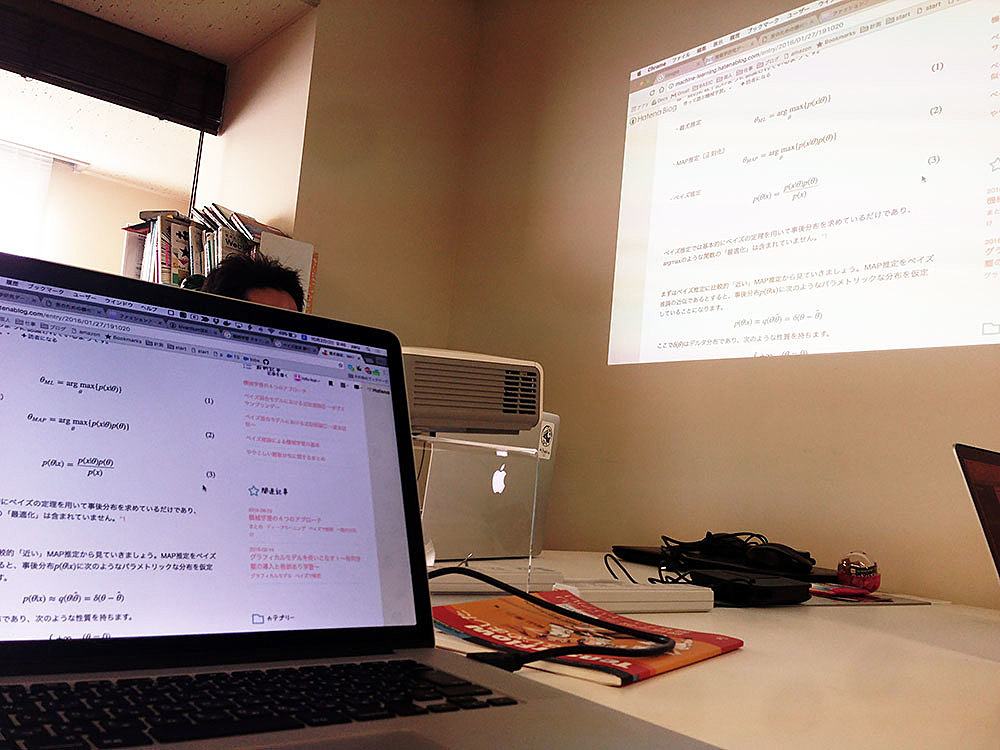
なぜやったのか
ここ数年間、ずっと機械学習の分野が熱いですね。最近ではTensorFlowをはじめ色々な機械学習のライブラリが出てきて初心者でもチュートリアルレベルのものなら、なんとなくできるようになってきました。もう少し先の未来では、機械学習の理論を完全に理解していなくても気軽に使えるような時代がくると思います。が、盛り上がっている今、手を出さないのはもったいないし、面白そう!というのと、この進化の過程を自ら少しでも体感しておくことが、この先の選択肢の幅を広げるんじゃないかと考えて、社内で初の機械学習ハッカソンを開催しました。
ちなみに、弊社では専門の機械学習エンジニア・データサイエンティストがいません。レベル感で言えば、独学〜大学研究レベルで、経験値的にも知識的にも低いです。特に僕は特段一番低いです。がんばらねば。
なお、データを投入して学習するのに普通に数時間とかかかるので、あまりハッカソン向きなものではないです。今回は精度を求めるというよりは機械学習でやりたいことのプロセスを体感するというのを主軸に置きました。機械学習が少しでもやれるぞという、キッカケ作りですね。

お昼のハンバーガーはめちゃ美味かったです…この時は、まさかあんな結末になろうとは…。
発表内容
ハッカソンは午前中にアイデアソンで機械学習でなにをするか…を皆でアイデアを出し合いながら、テーマが決まったらそれぞれ実装に入って、夕方に簡単に発表という流れでした。基本的に「できた!」と言えるような成果物はあまりなかったので、ダイジェスト的にお送りします!
Word2Vecをちゃんと理解したいと思いました。 @mochizuki
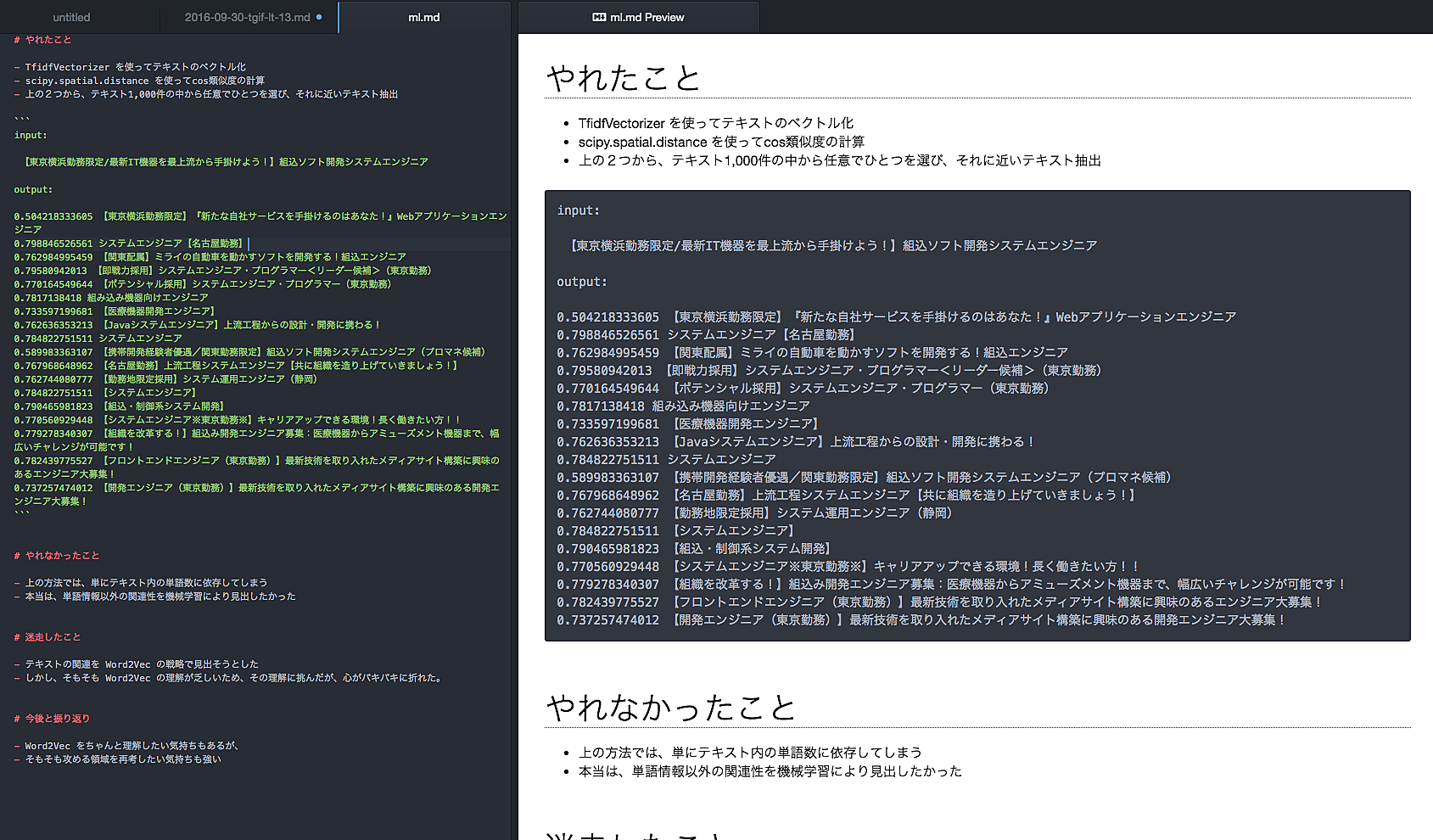
- TfidfVectorizerを使ってテキストのベクトル化
- sclpy, spatial, distanceを使ってcos類似度の計算
- 上の2つから、テキスト1,000件の中から任意で一つを選び、それに近いテキスト抽出
近いテキストの抽出はできていましたが、本来目指していた単語情報以外のメタデータを機械学習にかませるというのができなかった感じです。
堀北真希さんを探したい人生だった @zaru
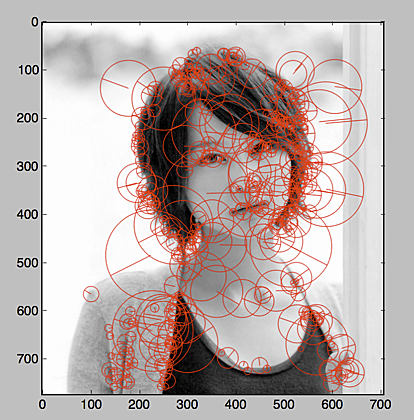
僕は定番の画像分類に挑戦しました。調べるとセクシー女優で学ぶ画像分類入門という記事が非常に分かりやすかったので、これを参考に実装を進めました。記事からの引用ですが、やったのは以下の様なことです。堀北真希さんの画像を集めて特徴抽出して、代表ベクトルとって判定させる感じ。
- OpenCVで画像特徴抽出
- K-means法でのクラスタリング
結果、一応動くものは出来ましたが、はっきり言って精度は全く出ず…同じような手法でやっている事例を見ると80%くらいは出てるので、なにかを間違えているような気がしてます。何が間違えているのかは見当がついていません。

灰色の部分が似ている画像と判定されたものたち…。うーん。
家庭菜園を捗らせたい - 画像で病害分類 - @mori
ferretのレコメンドエンジンを作った森ちゃんです。
ヤバそうな植物の画像を入れたら「こんな病害にやられてない?」って返してくれると幸せになれそう…という感じでTensorFlowに症例の画像を学習させていました。ただ、学習用のデータ量が少なかったのと、ちがう病害でも似たような見た目になることから精度は30%程度。時間の関係から1000回学習(40分)だったので、データ量増やして数時間学習させれば、もっと精度は上がりそうです。
トピックモデルでレコメンドがしたい @karasawa
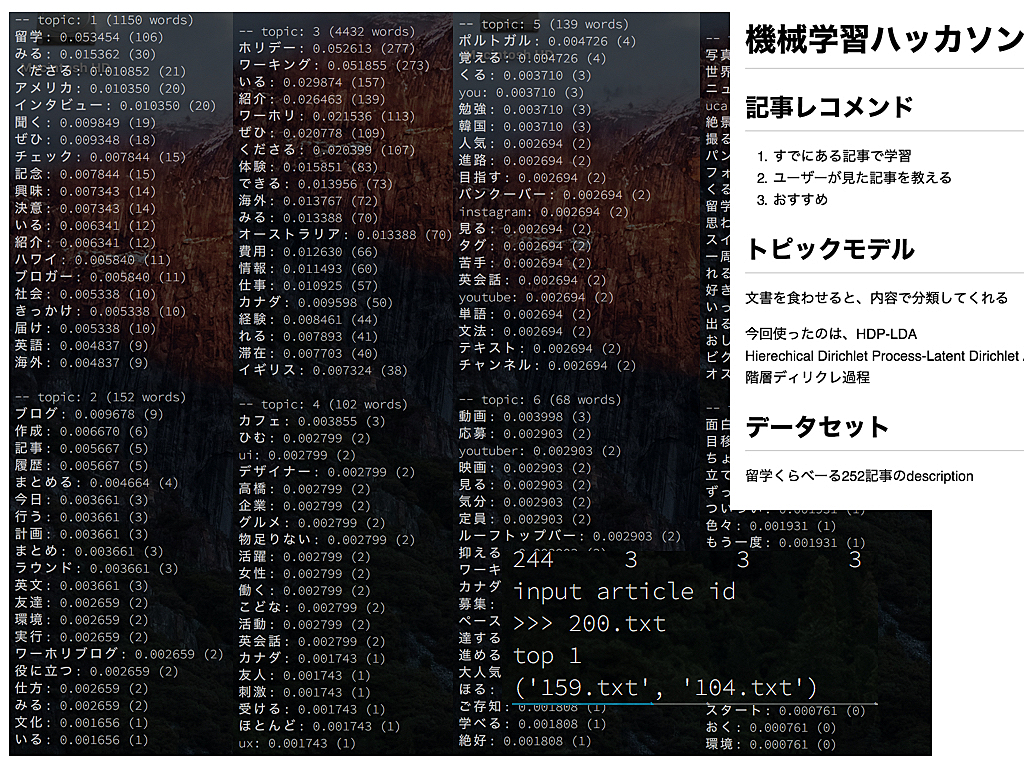
参考記事: トピックモデルを利用した対話アプリケーションの作成
猫の実写画像をボンドで絵を描く友人の画風に近づけようとしました @Ciger


chainer-goghというライブラリを使って、猫の画像とボンドの絵の画風を合成してました。けっこう良い感じにできていました。これでPrismaアプリが作れる!
ただイヌの画像とネコの画像を学習させて、イヌ・ネコ判定をやりたかった @ykyk1218
- イヌとネコの画像をbingAPIを使って取得
- tensorflowに流すようにCSVを作成
- イヌのダウンロードした画像をtensorflowで読み込む
- ネコのダウンロードした画像をtensorflowで読み込む
- イヌの画像をtensorflowに与えてテスト
コード: https://github.com/ykyk1218/tensorflow-hack
何トラマンに似ているかわかるやつを作ろうとした話〜夢見な僕とテンソルフロー〜 @shiraki
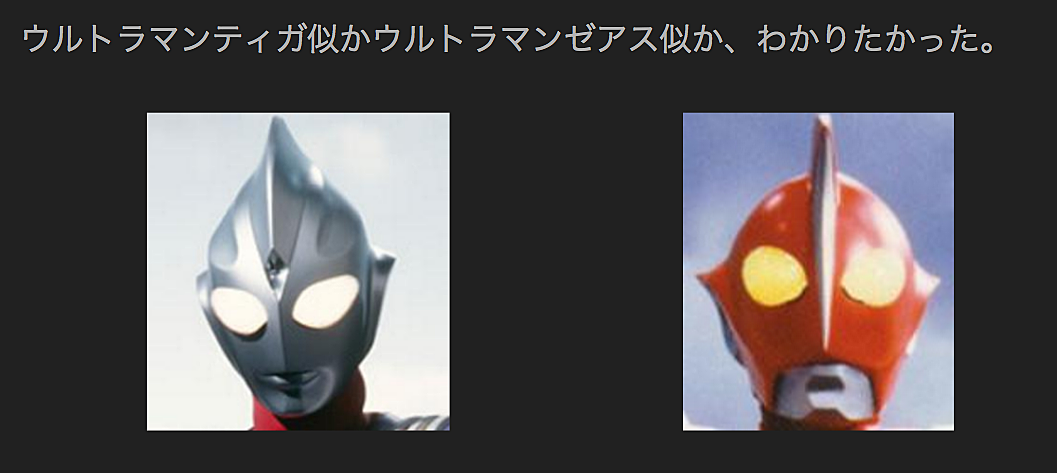
画像をTensorflowに食わせて判定させるも奇跡の0%! テストデータが足りないせいだと気がついて再度やると30%ほど。みんな30%程度になってるのは単にデータ量不足と学習回数が少ないからなのかな?
さいごに
やる前は割と一般的な手法でやるし、なんとかなるだろーと楽観的に考えていたんですが、いざ取り組み始めると、うまくいかないときのリカバーが非常に難しく、かといってワークアラウンド的な発想も出ずで、いったい俺は今何をやっているんだろう…?と思う瞬間が結構ありました。想像以上に難しく、きちんと学んでいかないと厳しいなぁと実感しました。正直、プログラミングを初めてやった時以上の無力さみたいなものを痛感しましたね…。とはいえ1日でどうこうなるようなものではないので、懲りずに継続して学んでいきたいと思います。誰か知見のある人に勉強会を開いてもらいたい…!